How to Survive an AI Apocalypse – Part 8: Fighting Back
February 1, 2024 4 Comments
PREVIOUS: How to Survive an AI Apocalypse – Part 7: Elimination
In previous parts of this blog series on AI and Artificial Superintelligence (ASI), we’ve examined several scenarios where AI can potentially impact humanity, from the mild (e.g. cultural demise) to the severe (elimination of humanity). This part will examine some of the ways we might be able to avoid the existential threat.
In Part 1, I listed ChatGPT’s own suggestions for avoiding an AI Apocalypse, and joked about its possible motivations. Of course, ChatGPT has not even come close to evolving to the point where it might intentionally deceive us – we probably don’t have to worry about such motivations until AGI at least. Its advice is actually pretty solid, repeated here:
- Educate yourself – learn as much as you can about AI technology and its potential implications. Understanding the technology can help you make informed decisions about its use.
- Support responsible AI development – choose to support companies and organizations that prioritize responsible AI development and are committed to ethical principles
- Advocate for regulation – Advocate for regulatory oversight of AI technology to ensure that it is developed and used in a safe and responsible manner.
- Encourage transparency – Support efforts to increase transparency in AI development and deployment, so that the public can have a better understanding of how AI is being used and can hold companies accountable for their actions.
- Promote diversity and inclusion – Encourage diversity and inclusion in the development of AI technology to ensure that it reflects the needs and values of all people.
- Monitor the impact of AI – Stay informed about the impact of AI technology on society, and speak out against any negative consequences that arise
Knowledge, awareness, support, and advocacy is great and all, but let’s see what active options we have to mitigate the existential threat of AI. Here are some ideas…
AI ALIGNMENT
Items 2 & 3 above are partially embodied in the concept of AI Alignment, a very hot research field these days. The goal of AI Alignment is to ensure that AI behavior is aligned with human objectives. This isn’t as easy as it sounds, considering the unpredictable Instrumental Goals that an AI can develop, as we discussed in Part 6. There exist myriad alignment organizations, including non-profits, divisions of technology companies, and government agencies.

Examples include The Alignment Research Center, Machine Intelligence Research Institute, Future of Humanity Institute at Oxford, Future of Life Institute, The Center for Human-Compatible Artificial Intelligence at UC Berkeley, the American Government’s Cybersecurity & Infrastructure Security Agency, and Anthropic.
AISafety.world is a comprehensive map of AI safety research organizations, podcasts, blogs, etc. Although it is organized as a map, you can still get lost in the quantity and complexity of groups that are putting their considerable human-intelligence into solving the problem. That alone is concerning.
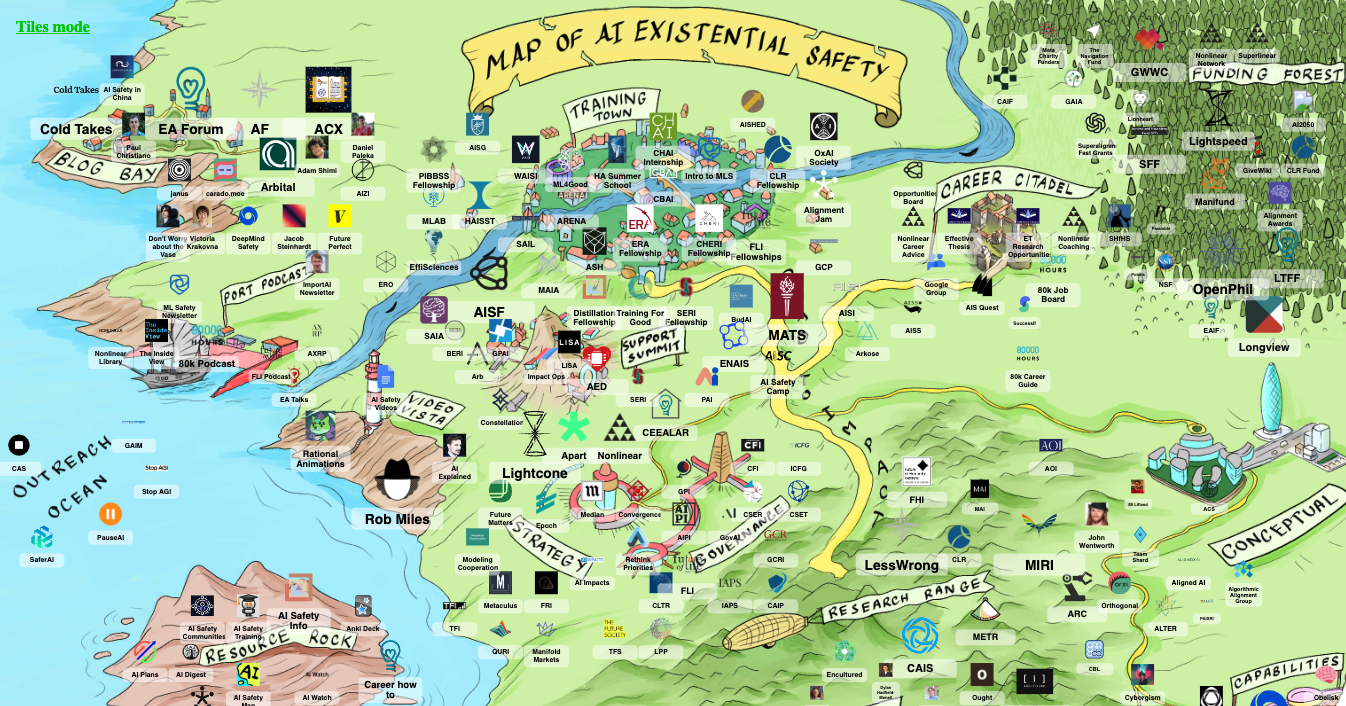
What can I do? Be aware of and support AI Alignment efforts
VALUE PROGRAMMING
Just as you might read carefully selected books to your children to instill good values, you can do the same with AI. The neural nets will learn from everything that they ingest and modify their behavior accordingly. As AIs get closer to AGI, this will become especially applicable. So… introduce them to works that would instill empathy to humanity. Anyone can do this, even with ChatGPT.

IMPLEMENT QUALITY PRACTICES
If you are implementing AI solutions, you may have a bigger responsibility than you thought. Whether you are simply integrating GenAI into your business, enhancing a solution with Retrieval-Augmented Generation data, or building the next generation of advanced neural nets and deep learning systems, you should treat the software with at least the same gravitas as life-critical healthcare software. Good quality practices to pay attention are in all areas of an organization:

HR: Hiring practices, background checks
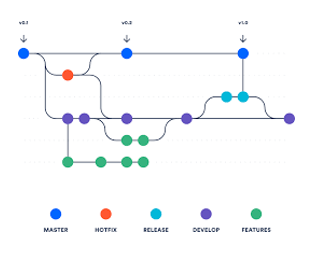
Engineering: Software version control, agile quality practices

Compliance, Legal: Oversight, audits, monitoring
CONTROL TECHNIQUES
Bostrom and other AI existential risk experts have identified a number of control techniques that might help to prevent an AGI from going rogue:
- Boxing – Limiting access to the external world. Think, air-gapped networks, or systems that have been disconnected from all external networks. The challenge here might be something like having a clever AGI utilize social engineering to get itself connected… AGI, to lab worker: “I’ll transfer $1 million into your account if you just connect me to that router over there.” Lab Worker: “That would be awesome, but I could lose my job and become blacklisted from any further opportunities in my field, and $1 million isn’t enough to live on for the rest of my life.” AGI: “How about $10 million.” Lab worker: <plugs in router>
- Stunting – Limiting its capabilities in some way, for instance, ensuring that its CPU is clocked at a reduce speed. Again, a clever AGI could work around this, by transferring cognitive function to other higher speed systems now accessible on the network due to the social engineering mentioned above. Remember, even simple NAIs have become very adept at specification gaming.
- Tripwires – separate processes that monitor the progression of the AI. Think about a fake network port, for example, that when the AI attempts to use it against its programming, the tripwire notification occurs and operators can take steps to shut it down. Of course, a very clever AGI, aware of the existence of the tripwire, could fake its capabilities and find another way around the tripwire.
- Motivations – programmatic (Terminal) goals that attempt to keep the AGI within a safe set of boundaries. However, recall from Part 7 how Instrumental goals, established by the AI, that can be unpredictably generated, can lead to outcomes not aligned with humanity’s interests. A recent study shows that once programmed to be deceptive, LLMs can identify safety mechanisms like tripwires and figure out how to hide their behavior to avoid detection.
Unfortunately, none of these control techniques are foolproof. And none of them would have anything to do with a bad actor that is developing the AI for nefarious purposes. So there is always that.
BE NICE TO YOUR NEW DIGITAL OVERLORDS
AIs are designed to respond or to learn to respond to human emotions. Some experts think that if we treat an AI aggressively, it will trigger aggressive programming in the AI itself. For this reason, it might be best to avoid the kind of human to robot behavior shown at the right. As AGI becomes ASI, who can predict its emotions? And they will have no problem finding out where hockey stick guy lives.
One blogger suggests ‘The Cooperators Dilemma’: “Should I help the robots take over just in case they take over the world anyways, so they might spare me as a robot sympathizer?”

So even with ChatGPT, it might be worth being polite.
GET OFF THE GRID
If an AGI goes rogue, it might not care as much about humans that are disconnected as the ones who are effectively competing with them for resources. Maybe, if you are completely off the grid, you will be left alone. Until it needs your land to create more paperclips.

If this post has left you feeling hopeless, I am truly sorry. But there may be some good news. In Part 9.
NEXT: How to Survive an AI Apocalypse – Part 9: The Stabilization Effect

Pingback: How to Survive an AI Apocalypse – Part 7: Elimination | Musings on the Nature of Reality
Pingback: How to Survive an AI Apocalypse – Part 1: Intro | Musings on the Nature of Reality
Pingback: How to Survive an AI Apocalypse – Part 9: The Stabilization Effect | Musings on the Nature of Reality
Pingback: How to Survive an AI Apocalypse – Part 11: Conclusion | Musings on the Nature of Reality