How to Survive an AI Apocalypse – Part 11: Conclusion
March 17, 2024 2 Comments
PREVIOUS: How to Survive an AI Apocalypse – Part 10: If You Can’t Beat ’em, Join ’em
Well, it has been a wild ride – writing and researching this blog series “How to Survive an AI Apocalypse.” Artificial Superintelligence, existential threats, job elimination, nanobot fog, historical bad predictions, Brain Computer Interfaces, interconnected minds, apocalypse lore, neural nets, specification gaming, predictions, enslavement, cultural demise, alignment practices and controlling the beast, UFOs, quantum mechanics, the true nature of reality, simulation theory and dynamic reality generation, transhumanism, digital immortality…
Where does it all leave us?
I shall attempt to summarize and synthesize the key concepts and drivers that may lead us to extinction, as well as those that may mitigate the specter of extinction and instead lead toward stabilization and perhaps even, an AI utopia. First, the dark side…
DRIVERS TOWARD EXTINCTION
- Competition – If there were only one source of AI development in the world, it might be possible to evolve it so carefully that disastrous consequences could be avoided. However, as our world is fragmented by country and by company, there will always be competition driving the pace of AI evolution. In the language of the 1950’s, countries will be worried about avoiding or closing an “AI gap” with an enemy and companies will be worried about grabbing market share from other companies. This results in sacrificing caution for speed and results, which inevitably leads to dangerous short cuts.
- Self-Hacking/Specification Gaming – All of the existential risk in AI is due to the unpredictability mechanisms described in Part 2, specifically the neural nets driving AI behavior, and the resultant possibilities of rewriting its own code. Therefore, as long as AI architecture is based on the highly complex neural net construct, we will not be able to avoid this apparent nondeterminism. More to the point, it is difficult to envision any kind of software construct that facilitates effective learning that is not a highly complex adaptive system.
- The Orthogonality Thesis – Nick Bostrom’s concept asserts that intelligence and the final goals of an AI are completely independent of each other. This has the result that mere intelligence cannot be assumed to make decisions that minimize the existential risk to humanity. We can program in as many rules, goals, and values as we want, but can never be sure that we didn’t miss something (see clear examples in Part 7). Further, making the anthropomorphism mistake of thinking that an AI will think like us is our blind spot.
- Weaponization / Rogue Entities – As with any advanced technology, weaponization is a real possibility. And the danger is not only the hands of so-called rogue entities, but also so-called “well meaning” entities (any country’s military complex) claiming that the best defense is having the best offense. As with the nuclear experience, all it takes is a breakdown in communication to unleash the weapon’s power.
- Sandbox Testing Ineffective – The combined ability of an AI to learn and master social engineering, hide its intentions, and control physical and financial resources makes any kind of sandboxing a temporary stop-gap at best. Imagine, for example, an attempt to “air gap” an AGI to prevent it from taking over resources available on the internet. What lab assistant making $20/hour is going to resist an offer from the AGI to temporarily connect it to the outside network in return for $1 billion in crypto delivered to the lab assistant’s wallet?
- Only Get 1 Chance – There isn’t a reset button on AI that gets out of control. So, even if you did the most optimal job at alignment and goal setting, there is ZERO room for error. Microsoft generates 30,000 bugs per month – what are the odds that everyone’s AGI will have zero?

And the mitigating factors…
DRIVERS TOWARD STABILIZATION
- Anti-Rogue AI Agents – Much like computer viruses and the cybersecurity and anti-virus technology that we developed to fight them, which has been fairly effective, anti-rogue AI agents may be developed that are out there on the lookout for dangerous rogue AGIs, and perhaps programmed to defeat them, stunt them, or at least provide notification that they exist. I don’t see many people talking about this kind of technology yet, but I suspect it will become an important part of the effort to fight off an AI apocalypse. One thing that we have learned from cybersecurity is that the battle between the good guys and the bad guys is fairly lopsided. It is estimated that there are millions of blocked cyberattack attempts daily around the world, and yet we rarely hear of a significant security breach. Even considering possible underreporting of breaches, it is most likely the case that the amount of investment going into cyberdefense far exceeds that going into funding the hacks. If a similar imbalance occurs with AI (and there is ample evidence of significant alignment investment), anti-rogue AI agents may win the battle. And yet, unlike with cybersecurity, it might only take one nefarious hack to kick off the AI apocalypse.
- Alignment Efforts – I detailed in Part 8 of this series the efforts that are going in to AI safety research, controls, value programming, and the general topic of addressing AI existential risk. And while these efforts my never be 100% foolproof, they are certainly better than nothing, and will most likely contribute to at least the delay of portentous ASI.
- The Stabilization Effect – The arguments behind the Stabilization Effect presented in Part 9 may be difficult for some to swallow, although I submit that the more you think and investigate the topics therein, the easier it will become to accept. And frankly, this is probably our best chance at survival. Unfortunately, there isn’t anything anyone can do about it – either it’s a thing or it isn’t.
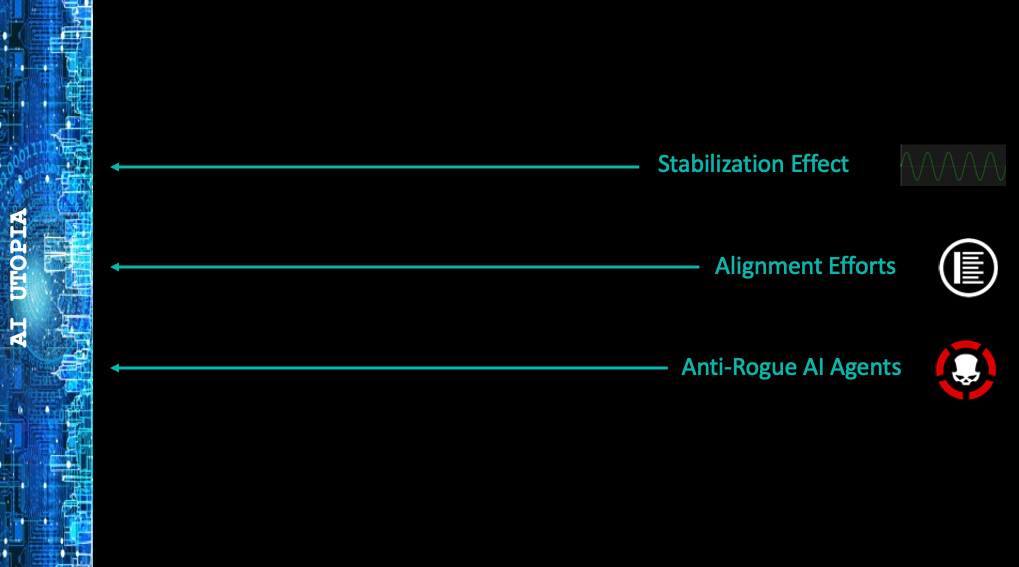
But if it is a thing, as I suspect, if ASI goes apocalyptic, the The Universal Consciousness System may reset our reality so that our consciousnesses continues to have a place to learn and evolve. And then, depending on whether or not our memories are erased, either:
It will be the ultimate Mandela effect.
Or, we will simply never know.